AKTUELLE NEWS AUS DER KI-WELT

SCHWEDENS NATIONALBIBLIOTHEK FÜTTERT KI MIT DATEN AUS 500 JAHREN

Die Datenabteilung KBLab der Schwedischen Nationalbibliothek fasst Tausende von Werken zu einem Datensatz zusammen. Damit werden KI-Modelle trainiert.
Per Gesetz hat die Schwedische Nationalbibliothek praktisch alle schwedischsprachigen Schriften der letzten 500 Jahre gesammelt. Insgesamt 16 Petabyte sind so bereits zusammengekommen, jeden Monat wächst die Sammlung um 50 Terabyte.
Auf dieser Basis hat die 2019 gegründete, integrierte Forschungsabteilung KBLab mehr als zwei Dutzend KI-Modelle trainiert. „Bevor unser Labor eingerichtet wurde, konnten Forscher nicht auf einen [gesammelten] Datensatz in der Bibliothek zugreifen – sie mussten sich jeweils ein einzelnes Objekt ansehen“, so Direktor Love Börjeson.
Hoch spezialisierte Datensätze für die Forschung
Dank dieser Arbeit sollen Forscherinnen und Forscher bald in der Lage sein, hoch spezialisierte Datensätze zu erstellen, „zum Beispiel aus jeder schwedischen Postkarte, auf der eine Kirche abgebildet ist, aus jedem Text, der in einem bestimmten Stil geschrieben ist, oder aus jeder Erwähnung einer historischen Figur in Büchern, Zeitungsartikeln und Fernsehsendungen“, heißt es im Nvidia-Blog. Für das Training wurde Hardware des Grafikprozessorherstellers verwendet.
Beim ersten Modell waren es noch 20 GB Daten, heute sind es laut Hugging Face etwa 70 GB. Demnächst soll das KBLab sogar ein ganzes Terabyte schwedischer Texte in Angriff nehmen. Der Datensatz wird dann neben Schwedisch auch Niederländisch, Norwegisch und Deutsch enthalten. Damit soll die Leistung der KI-Modelle verbessert werden.
Generatives Textmodell in der Entwicklung
Zusätzlich zu den Transformer-Modellen, die schwedischen Text verstehen, verfügt KBLab über ein KI-Tool, das Ton in Text umwandelt und es der Bibliothek ermöglicht, ihre umfangreiche Sammlung von Radiosendungen zu transkribieren, damit Forschende die Audioaufnahmen nach bestimmten Inhalten durchsuchen können.
KBLab entwickelt derzeit auch generative Textmodelle und ein KI-Modell zur automatischen Erstellung von Beschreibungen von Videoinhalten. In Zusammenarbeit mit Forschenden der Universität Göteborg und der Schwedischen Akademie unterstützt KBLab die Modernisierung von Wörterbüchern.
Zusammenfassung
- Damit Wissenschaftler:innen hochpräzise Datensätze aus mehreren Jahrhunderten schwedischer Texte extrahieren können, trainiert die Schwedische Nationalbibliothek KI-Modelle mit Tausenden von Werken.
- Die ersten KI-Modelle basieren auf etwa 70 Gigabyte Daten.
- Jeden Monat wächst die Bibliothek jedoch um etwa 50 Terabyte, weshalb das Datentraining auf noch größere KI-Modelle ausgeweitet werden soll.
Quellen: Nvidia, Hugging Face
GPT - 4 KÖNNTE DIE US-RECHTSANWALTSPRÜFUNG BESTEHEN

Forschende testen GPT-3.5 mit Fragen des US Bar Exams. Sie prognostizieren, dass GPT-4 und vergleichbare Modelle die Prüfung zeitnah bestehen werden.
In den USA verlangen fast alle Gerichtsbarkeiten eine Prüfung zur Berufszulassung, bekannt als das US „Bar Exam“. Mit Bestehen dieser Prüfung erlangen Jurist:innen die Zulassung in eine Anwaltskammer eines amerikanischen Bundesstaats.
In den meisten Fällen müssen Bewerber:innen davor mindestens sieben Jahre eine weiterführende Ausbildung beenden, davon drei Jahre an einer anerkannten juristischen Fakultät.
Die Vorbereitung des Examens nimmt Wochen bis Monate in Anspruch und etwa eine von fünf Personen fällt beim ersten Versuch durch. Forschende des Chicago Kent College of Law, der Bucerius Law School Hamburg und des Stanford Center for Legal Informatics (CodeX) haben jetzt untersucht, wie sich OpenAIs GPT-3.5-Modell, das auch als Grundlage von ChatGPT dient, im Bar Exam schlägt.
OpenAIs GPT-3.5 ist nicht auf Rechtstexte spezialisiert
OpenAIs GPT-3.5 und ChatGPT zeigen in verschiedenen Szenarien der Verarbeitung natürlicher Sprache beeindruckende Leistungen und überholen oft Modelle, die explizit für bestimmte Domänen trainiert wurden. Die Trainingsdaten für die GPT-Modelle sind nicht komplett bekannt, die Modelle hätten jedoch mit hoher Wahrscheinlichkeit Rechtstexte aus öffentlichen Quellen gesehen, schreibt das Forschungsteam.
Angesichts der komplexen Natur juristischer Sprache und des eher offenen Trainings von GPT-3.5 sei es eine offene Frage, ob GPT oder vergleichbare Modelle erfolgreich juristische Aufgaben bewerten könnten.
Das Team testet OpenAIs großes Sprachmodell daher mit einem mehrstufigen Multiple-Choice-Teil des Bar Exams, bekannt als Multistate Bar Examination (MBE). Für die Tests verwenden die Forschenden ausschließlich Zero-Shot-Prompts.
Das MBE ist Teil des kompletten Exams, umfasst etwa 200 Fragen und soll juristisches Wissen und Leseverständnis testen. Laut der Forschenden erfordern die fiktiven Szenarien eine überdurchschnittliche semantische und syntaktische Beherrschung der englischen Sprache.
Ein Beispiel sieht so aus:
Question: A man sued a railroad for personal injuries suffered when his car was struck by a train at an unguarded crossing. A major issue is whether the train sounded its whistle before arriving at the crossing. The railroad has offered the testimony of a resident who has lived near the crossing for 15 years. Although she was not present on the occasion in question, she will testify that, whenever she is home, the train always sounds its whistle before arriving at the crossing.
Is the resident’s testimony admissible?
(A) No, due to the resident’s lack of personal knowledge regarding the
incident in question.
(B) No, because habit evidence is limited to the conduct of persons,
not businesses.
(C) Yes, as evidence of a routine practice.
(D) Yes, as a summary of her present sense impressions.
GPT-3.5 fällt durch, doch GPT-4 könnte das Bar Exam knacken
Für den Test nutzte das Team Vorbereitungsmaterial der National Conference of Bar Examiners (NCBE), der Organisation, die den Großteil der Bar Exams erstellt. GPT-3.5 konnte mit unterschiedlichen Prompts korrekte Antworten auf die Fragen geben, am erfolgreichsten war jedoch ein Prompt, der das Modell aufforderte, die Top-3 Antworten zu ordnen.
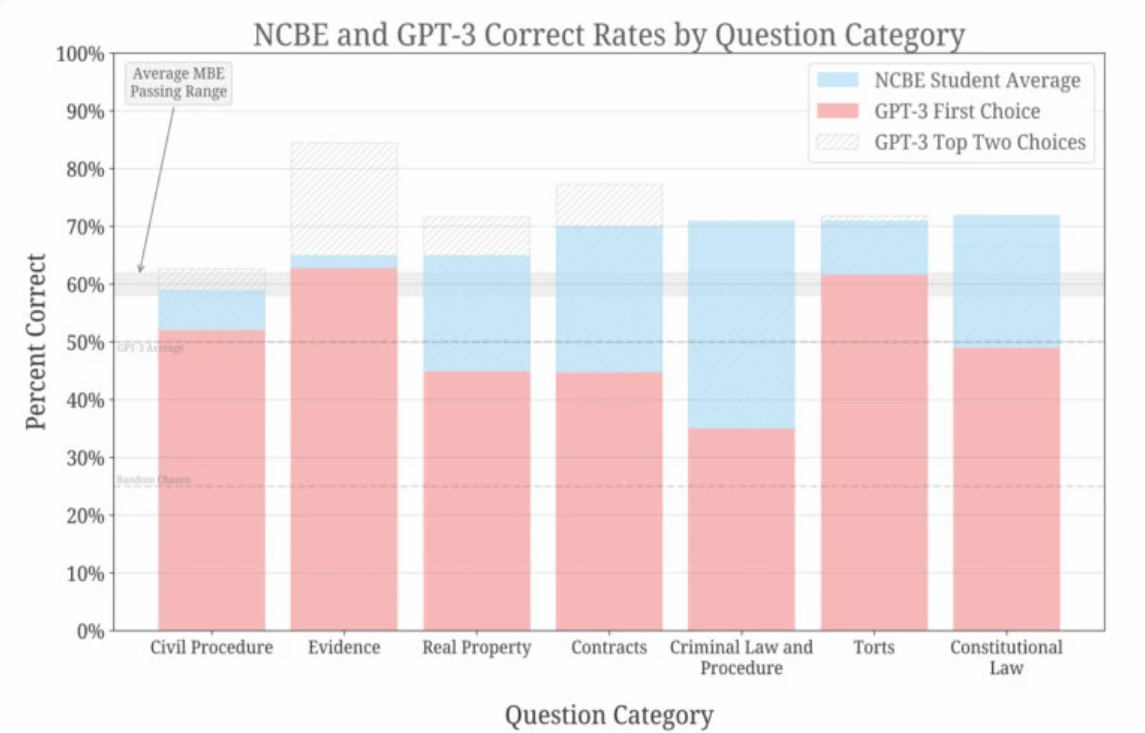
Zusammenfassung der Leistungen nach Fragekategorien für GPT-3.5 und vom NCBE erfasste Teilnehmende. | Bild: Bommarito, Katz et al.
Im Schnitt liegt GPT-3.5 etwa 17 Prozent hinter menschlichen Teilnehmenden, die Unterschiede reichen jedoch von wenigen Prozenten bis zu 36 Prozent in der Kategorie Strafrecht. In der Kategorie Beweise schafft es GPT-3.5 über die durchschnittlich notwendigen 60 Prozent.
Mit der Top-3-Methode findet sich dagegen die richtige Antwort in fast allen Kategorien vielfach unter den ersten zwei Antworten. Laut des Teams überschreitet das Modell dabei deutlich die Baseline Zufall von 50 Prozent.
Bei allen Prompts und Hyperparametern übertraf GPT-3.5 die Basisrate des Zufalls deutlich. Ohne jegliche Feinabstimmung erreicht es derzeit eine Bestehensrate in zwei Kategorien des Bar Exams und erreicht in einer Kategorie die gleiche Rate wie menschliche Testteilnehmer. Die Rangfolge der möglichen Antworten korreliert stark mit der Korrektheit und übertrifft die Zufallsrate, was ein allgemeines Verständnis des juristischen Bereichs durch das Modell bestätigt.
Aus dem Paper
GPT-3.5 übertreffe deutlich die erwartete Leistung, schreiben die Autoren: „Trotz Tausender von Stunden, die wir in den vergangenen zwei Jahrzehnten mit ähnlichen Aufgaben verbracht haben, haben wir nicht erwartet, dass GPT-3.5 eine derartige Leistungsfähigkeit in einem Zero-Shot-Szenario mit minimalem Modellierungs- und Optimierungsaufwand zeigen würde.“
Die Geschichte der Entwicklung großer Sprachmodelle suggeriere daher stark, dass solche Modelle den getesteten Teil des Bar Exam bestehen könnten. Aufgrund von Erfahrungsberichten von GPT-4 und der Bloom-Modellfamilie von LAION halten die Forschenden dieses Szenario innerhalb der nächsten 18 Monate für realistisch.
Im nächsten Schritt will das Team die Abschnitte Essay (MEE) und situative Leistung (MPT) des Bar Exams testen.
Google Brain zeigte kürzlich eine mit medizinischen Daten optimierte Version des großen Sprachmodells PaLM, das Laien-Fragen zu Medizinthemen auf Augenhöhe mit menschlichen Expert:innen beantworten kann. Es übertrifft die Leistung des nativen PaLM-Sprachmodells deutlich.
Zusammenfassung
- Ein Team von Forschenden hat OpenAIs GPT-3.5-Modell im US „Bar Exam“ getestet, eine Prüfung zur Berufszulassung für Juristen.
- Es testete GPT-3.5 mit dem Multiple-Choice-Teil des Bar Exams, dem Multistate Bar Examination (MBE). Das MBE umfasst etwa 200 Fragen und testet juristisches Wissen und Leseverständnis.
- GPT-3.5 hat dabei die Erwartungen deutlich übertroffen. Die Forschenden halten es für möglich, dass GPT-4 den Test besteht.
Quellen: Paper, Github
AI LEADERS – DER FONDS
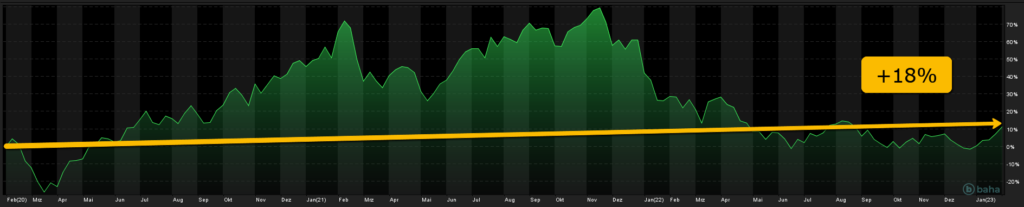
Starke Unternehmen für ein gutes Jahr 2023
Mit großem Schwung sind wir in das neue Jahr gestartet. Der AI Leaders konnte seit Jahresbeginn einen Zuwachs von über 12% erwirtschaften.
Das zurückliegende Jahr 2022 war dagegen geprägt von Licht und Schatten. Vor allem renditeseitig war das Jahr 2022 nicht erfreulich, sondern vielmehr das schwächste Jahr des AI Leaders Fonds überhaupt.
Einmal mehr möchte ich betonen, dass die Kursrückgänge in der ersten Jahreshälfte des abgelaufenen Jahres ausschließlich durch exogene Faktoren getrieben waren. Die anziehende Inflation, die steigenden Zinsen, der Ukraine-Krieg, Energiesorgen und geopolitische Spannungen haben die Märkte zutiefst verunsichert.
Unsere Unternehmen haben ihren Wachstumspfad jedoch unbeirrt fortgesetzt und sind im Jahr 2022 voraussichtlich im Durchschnitt um rund 20 % bei Umsatz und Gewinn gewachsen. Das ist der Nährboden für die kräftige Erholung der letzten Wochen gewesen und wird es auch für die zukünftige Entwicklung sein.
Insgesamt sehen wir unsere Depots und die Depotunternehmen bestens aufgestellt für das vor uns liegende Jahr. Das ist der wesentliche Grund dafür, dass wir durchaus optimistisch auf das Jahr 2023 blicken. Unsere Unternehmen werden mit hoher Wahrscheinlichkeit weitere Umsatz- und Gewinnzuwächse verzeichnen können. Aber auch andere Gründe, die außerhalb unseres Einflussbereichs liegen, sprechen für ein gutes Börsenjahr. Allen voran sollte das Ende der massiven Anstiege bei den Zinsen einer der wesentlichen Faktoren sein.
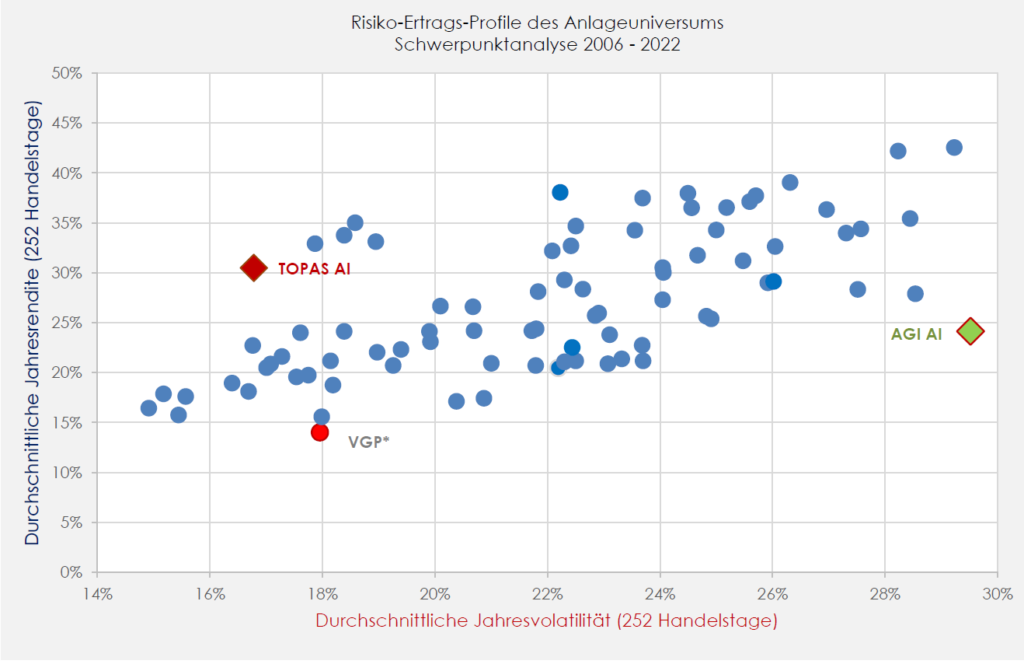
Insbesondere nach Einführung von dem Riskmanagement TOPAS im Sommer 2022, konnte sich der AI Leaders von seiner Konkurrenz deutlich absetzen.
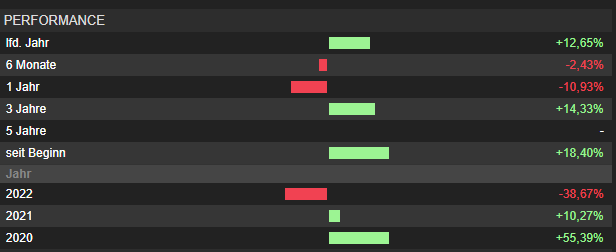
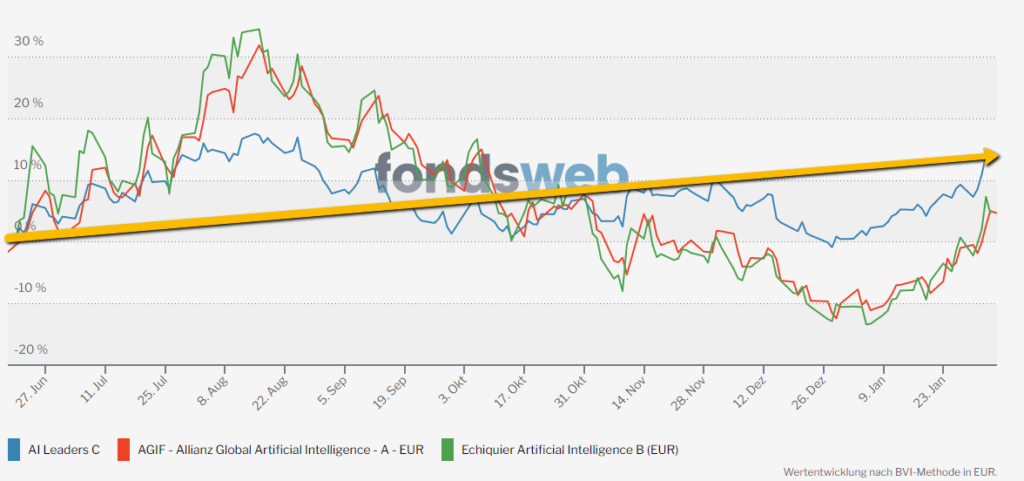
Entwicklung über die letzten 12 Monate:
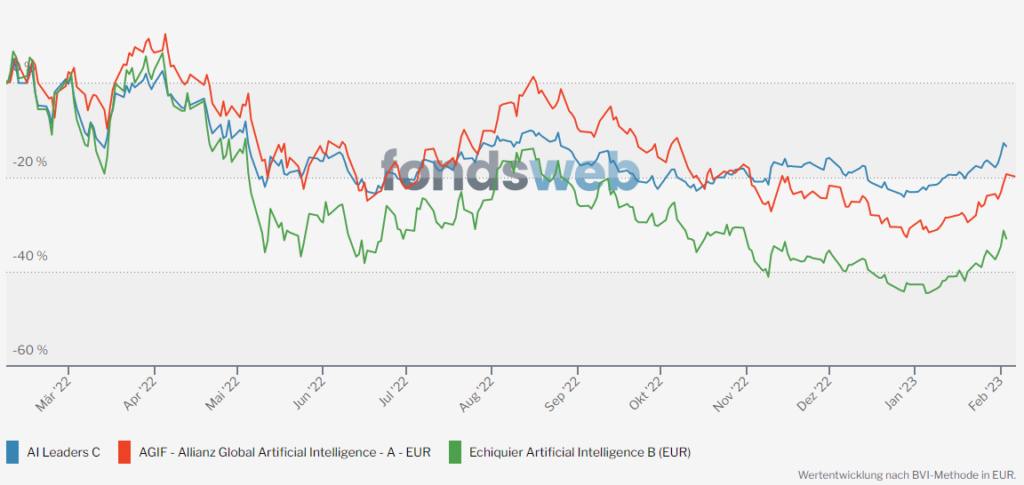
Entwicklung seit Tiefststand am 20.06.2022:
Risiko-Ertragsprofile 2006-2022:
Die nächste Feuerprobe konnte TOPAS auch erfolgreich bestehen. In der Aufwärtsphase liegen wir gleichauf mit der Konkurrenz von Allianz und Echiquier.
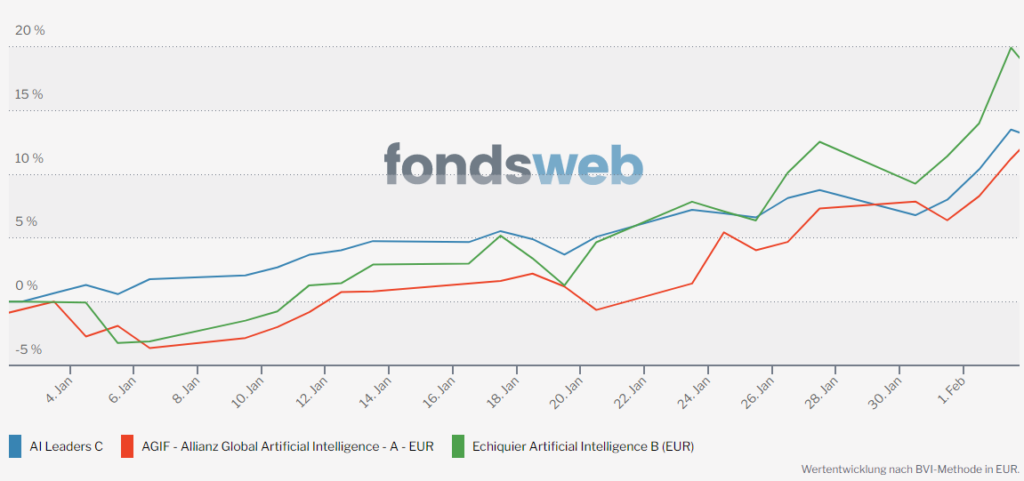
Für das Jahr 2023 haben wir die besten Voraussetzungen geschaffen die Depots mit den besten KI Unternehmen zu bestücken, um die bestmöglichen Voraussetzungen für eine nachhaltig positive Entwicklung unserer Fonds zu ermöglichen.
Für weitere Fragen stehe wir Ihnen wie immer gerne zur Verfügung.
Herzliche Grüße aus Stuttgart
Tilmann Speck
Christian Hintz
Gerd Schäfer